
Continuous Integration (original version)
An important part of any software development process is getting reliable builds of the software. Despite it's importance, we are often surprised when this isn't done. Here we discuss the process that Matt has put into place on a major project at Thoughtworks, a process that is increasingly used throughout the company. It stresses a fully automated and reproducible build, including testing, that runs many times a day. This allows each developer to integrate daily thus reducing integration problems.
10 September 2000

This article is now superseded by a more up to date version
Software development is full of best practices which are often talked about but seem to be rarely done. One of the most basic, and valuable, of these is a fully automated build and test process that allows a team to build and test their software many times a day. The idea of a daily build has been talked about a lot. McConnnell recommends it as a best practice and it's been long known as a feature of the Microsoft development approach. We agree with the XP community, however, in saying that daily builds are a minimum. A fully automated process that allows you to build several times a day is both achievable and well worth the effort.
We are using the term Continuous Integration, a term used as one of the practices of XP (Extreme Programming). However we recognize that the practice has been around for a long time and is used by plenty of folks that would never consider XP for their work. We've been using XP as a touchstone in our software development process and that influences a lot of our terminology and practices. However you can use continuous integration without using any other parts of XP - indeed we think it's an essential part of any competent software development activity.
There are several parts to making an automated daily build work.
- Keep a single place where all the source code lives and where anyone can obtain the current sources from (and previous versions)
- Automate the build process so that anyone can use a single command to build the system from the sources
- Automate the testing so that you can run a good suite of tests on the system at any time with a single command
- Make sure anyone can get a current executable which you are confident is the best executable so far.
All of this takes a certain amount of discipline. We've found that it takes a lot of energy to introduce it into a project. We've also found that once installed, it doesn't take too much effort to keep it up.
The Benefits of Continuous Integration
One of the hardest things to express about continuous integration is that makes a fundamental shift to the whole development pattern, one that isn't easy to see if you've never worked in an environment that practices it. In fact most people do see this atmosphere if they are working solo - because then they only integrate with themself. For many people team development just comes with certain problems that are part of the territory. Continuous integration reduces these problems, in exchange for a certain amount of discipline.
The fundamental benefit of continuous integration is that it removes sessions where people spend time hunting bugs where one person's work has stepped on someone else's work without either person realizing what happened. These bugs are hard to find because the problem isn't in one person's area, it is in the interaction between two pieces of work. This problem is exacerbated by time. Often integration bugs can be inserted weeks or months before they first manifest themselves. As a result they take a lot of finding.
With continuous integration the vast majority of such bugs manifest themselves the same day they were introduced. Furthermore it's immediately obvious where at least half of the interaction lies. This greatly reduces the scope of the search for the bug. And if you can't find the bug, you can avoid putting the offending code into the product, so the worst that happens is that you don't add the feature that also adds the bug. (Of course you may want the feature more than you hate the bug, but at least this way it's an informed choice.)
Now there's no guarantee that you get all the integration bugs. The technique relies on testing, and as we all know testing does not prove the absence of errors. The key point is that continuous integration catches enough bugs to be worth the cost.
The net result of all this is increased productivity by reducing the time spent chasing down integration bugs. While we don't know of anyone who's given this anything approaching a scientific study the anecdotal evidence is pretty strong. Continuous Integration can slash the amount of time spent in integration hell, in fact it can turn hell into a non-event.
The More Often the Better
There's a fundamental counter-intuitive effect at the center of continuous integration. It is that it is better to integrate often than to integrate rarely. For those that do it, this is obvious; but for those that haven't this seems like a contradiction to direct experience.
If you integrate only occasionally, such as less than daily, then integration is a painful exercise, one that takes a lot of time and energy. Indeed it's sufficiently awkward that the last thing you want to do is do it more frequently. The comment we often hear is “on a project this big, you can't do a daily build.”
Yet there are projects that do. We build a couple of dozen times a day on a code base around two hundred thousand lines of code worked on by a team of fifty people. Microsoft does daily builds on projects with tens of millions of lines of code.
The reason that this is possible is that the effort of integration is exponentially proportional to the amount of time between integrations. Although we're not aware of any measurements for this, this means that integrating once a week does not take five times as long as integrating once a day, but more like twenty-five times as long. So if your integration is painful, you shouldn't take this as a sign that you can't integrate more frequently. Done well, more frequent integration should be painless and you end up spending much less time carrying out the integration.
A key for this is automation. Most of integration can, and should, be done automatically. Getting the sources, compiling, linking, and significant testing can all be done automatically. At end you should be left with a simple indication of whether the build worked: yes or no. If yes you ignore it, if no you should be able to easily undo the last change to the configuration and be certain the build will work this time. No thought should be required to get a working build.
With an automated process like this, you can build as frequently as you like. The only limitation is the amount of time it takes to do the build.
What Is a Successful Build?
An important thing to decide is what makes a successful build. It may seem obvious, but it's remarkable how this can get muddy. Martin once reviewed a project. He asked if the project did a daily build and was answered in the affirmative. Fortunately Ron Jeffries was there to probe further. He asked the question “what do you do with build errors?” The response was “we send an e-mail to the relevant person”. In fact the project hadn't succeeded in a build for months. That's not a daily build, that's a daily build attempt.
We are pretty aggressive about what we mean by a successful build.
- All the latest sources are checked out of the configuration management system
- Every file is compiled from scratch
- The resulting object files (Java classes in our case) are linked and deployed for execution (put into jars).
- The system is started and suite of tests (in our case, around 150 test classes) is run against the system.
- If all of these steps execute without error or human intervention and every test passes, then we have a successful build
Most people consider a compile and link to be a build. At the least we think a build should include starting the application and running some simple tests against it (McConnnell used the term “smoke test”: switch it on and see if smoke comes out). Running a more exhaustive set of tests greatly improves the value of continuous integration, so we prefer to do that as well.
Single Source Point
In order to integrate easily, any developer needs to be able to get a full set of current sources easily. There's nothing worse than having to go around to different developers to ask for the latest bits and then having to copy them over, figure out where to put them, all this before you can begin the build.
The standard is simple. Anyone should be able to bring a clean machine, connect it to the network, and with a single command bring down every source file that's needed to build the system under development.
The obvious (we hope) solution is to use a configuration management (source control) system as the source of all code. Configuration management systems are usually designed to be used over a network and have the tools that allow people to easily get hold of sources. Furthermore they also include version management so you can easily find previous versions of various files. Cost shouldn't be an issue as CVS is an excellent open-source configuration management tool.
For this to work all source files should be kept in the configuration management system. All is often more than people think. It also includes build scripts, properties files, database schema DDLs, install scripts, and anything else that's needed to build on a clean machine. Too often we've seen code controlled, but not some other vital file that has to be found.
Try to ensure everything is under a single source tree in the configuration management system. Sometimes people use separate projects in the configuration management system for different components. The trouble with this is then people have to remember which versions of which components work with which versions of other components. For some situations you have to separate the sources, however these situations are much rarer than you think. You can build multiple components from a single tree of sources, such issues should be handled by the build scripts, not by the storage structure.
Automated Build Scripts
If you're writing a small program with a dozen or so files, then building the application may be just a matter of a single command to a compiler: javac *.java. Bigger projects need rather more. In these cases you have files in many directories. You need to ensure the resulting object code is in the proper place. As well as compilations there may be link steps. You have code generated from other files that needs to be generated before you can compile. Tests need to be run automatically.
A big build often takes time, you don't want to do all of these steps if you've only made a small change. So a good build tool analyzes what needs to be changed as part of the process. The common way to do this is to check the dates of the source and object files and only compile if the source date is later. Dependencies then get tricky: if one object file changes those that depend on it may also need to be rebuilt. Compilers may handle this kind of thing, or they may not.
Depending on what you need, you may need different kinds of things to be built. You can build a system with or without test code, or with different sets of tests. Some components can be built stand-alone. A build script should allow you to build alternative targets for different cases.
Once you get past a simple command line, scripts often handle the load. These might be shell scripts or use a more sophisticated scripting language such as perl or python. But soon it makes sense to use an environment designed for this kind of thing, such as the make tools in Unix.
In our Java development we quickly discovered we needed a more serious solution. Indeed Matt put a good bit of time into developing a build tool called Jinx which was designed for Enterprise Java work. Recently, however, we have switched over to the open-source build tool Ant. Ant has a very similar design to Jinx, allowing us to compile Java files and package them into Jars. It also makes it easy for us to write our own extensions to Ant to allow us to do other tasks within the build.
Many of us use IDEs, and most IDEs have some kind of build management process within them. However these files are always proprietary to the IDE and often fragile. Furthermore they need the IDE to work. IDE users set up their own project files and use them for individual development. However we rely on Ant for main builds and the master build is run on a server using Ant.
Self-Testing Code
Just getting a program to compile is not enough. While compilers in strongly typed languages can spot many problems, there are too many errors that even a successful compile lets through. To help track these down we put a lot of emphasis on an automated testing discipline - another practice that's advocated by XP.
XP divides tests into two categories: unit tests and acceptance (also called functional) tests. Unit tests are written by developers and typically test an individual class or small group of classes. Acceptance tests are usually written by customers or an outside test group (with the help of developers) and test the whole system end-to-end. We use both kinds of test, and automate both kinds of test as much as possible.
As part of the build we run a suite of tests that we call the “BVT” (Build Verification Tests). All the tests in the BVT must pass in order for us to have a successful build. All of the XP-style unit tests are in the BVT. As this article is about the build process, we'll mostly talk about the BVT here, just bear in mind that there is a second line of testing in addition to what's in the BVT, so don't judge the whole testing and QA effort by the BVT alone. Indeed our QA group doesn't ever see code unless it's passed the BVT since they only work on working builds.
The basic principle is that when developers are writing code they also write tests for that code. When they complete a task, not just do they check in the production code, they also check in the tests for that code. Those that follow XP closely use the test first style of programming: you shouldn't write any code until you have a failing test. So if you want to add a new feature to the system, you first write a test that will only work if the feature is there, then you make that test work.
We write the tests in Java, the same language that we're developing in. This makes writing tests just the same as writing code. We use JUnit as the framework for organizing and writing tests. JUnit is a simple framework that allows you to quickly write tests, organize them into suites, and run suites interactively or in batch mode. (JUnit is the Java member of the xUnit family - for which there are versions for almost every language.)
Developers typically run some subset of the unit tests with every compile as they are writing the software. This actually speeds up the development work since the tests help to find any logic errors in the code you're working on. Then, rather than debugging, you can look at the changes since you last ran the tests. Those changes should be small and thus it's a lot easier to find the bug.
Not everyone works strictly in the XP test-first style, but the key benefit comes from writing the tests at the same time. As well as making an individual task go faster, it also builds up the BVT making it more likely to catch errors. Since the BVT runs several times a day, this means that any problems that the BVT detects are easier to find for the same reason: we can look at a small amount of changed code in order to find the bug. This debugging by looking at the changed code is often much more effective than debugging by stepping though running code.
Of course you can't count on tests to find everything. As it's often been said: tests don't prove the absence of bugs. However perfection isn't the only point at which you get payback for a good BVT. Imperfect tests, run frequently, are much better than perfect tests that are never written at all.
A related question is the issue of developers writing tests on their own code. It's often been said that people should not test their own code, because it's too easy to overlook errors in your own work. While this is true, the self-testing process requires a rapid turn-around of tests into the code base. The value of that fast turn-around is greater than the value of separate testers. So for the BVTs we rely on developer-written tests, but there are separate acceptance tests which are written independently.
Another important part of self-testing is to improve the quality of tests with feedback - a key value of XP. Feedback here comes in the form of bugs that escaped the BVT. The rule here is that you aren't allowed to fix a bug until you have a failing unit test in the BVT. This way every time you fix a bug, you also add a test to ensure it doesn't slip past you again. Furthermore this test should lead you to think of other tests that need to be written to strengthen the BVT.
The Master Build
Build automation makes a lot of sense for individual developers, but where it really shines is in producing a master build for the whole team. We've found that having a master build procedure brings the team together and makes it easier to find integration problems early.
The first step is to choose a machine to run the master builds. We use Trebuchet (we played Age of Empires a lot) a four processor server which is pretty much dedicated to the build process. (In the early days when builds took a long time this horse-power was essential.)
The build process is in a Java class that's always running. If there's no build going on the build process sits in a while loop checking the repository every few minutes. If nobody's checked in any code since the last build, it continues to wait. If there's new code in the repository, then it starts building.
The first stage of the build is to do a full check out from the repository. Starteam provides a pretty good API for Java, so it was straightforward to hook into the repository. The build daemon looks at the repository at five minutes before the current time and sees if anyone checked in during that last five minutes. If so it considers it safe to check out the code as of five minutes ago (this prevents checking out in the middle of someone checking in, without locking the repository.)
The daemon checks out to a directory on Trebuchet. Once all is checked out the daemon then invokes the ant script in the directory. Ant then takes over to do a full build. We do a full build from all the sources. The ant script goes as far as compiling and dividing the resulting class files into half a dozen jars for deploying into the EJB server.
Once Ant has done the compiling and deployment, the build daemon starts the EJB server with new jars and executes the BVT test suite. The tests run, if all pass then we have a successful build. The build daemon then goes back into Starteam and labels the sources that were checked out with a build number. It then looks to see if anyone's checked in while it was building, if so it starts another build. If not the daemon goes back into its while loop and waits for the next check in.
At the end of the build, the build daemon sends an e-mail to all developers that had newly checked in code with that build. The e-mail summarizes the status of that build. It's considered bad form to leave the building after checking in code until you've got that e-mail.
The daemon writes a log of all its steps to an XML log file. A servlet runs on Trebuchet which allows anyone to see the state of the build by inspecting the log.
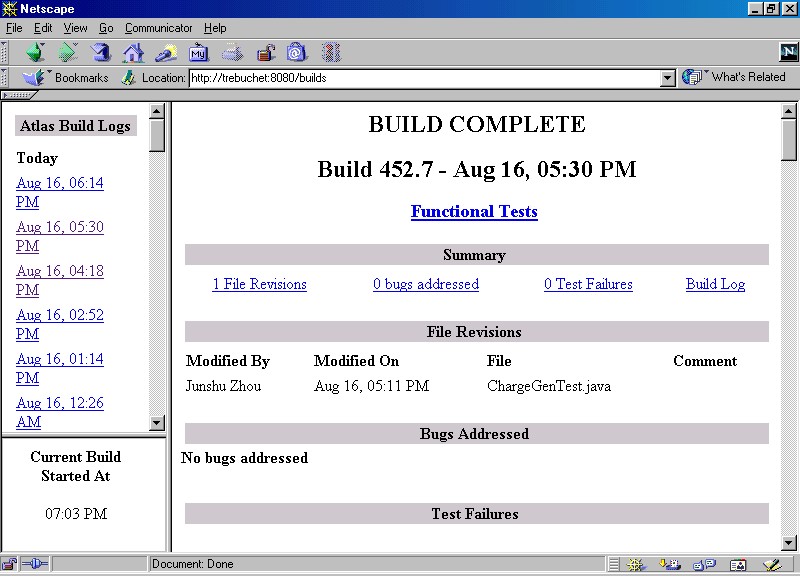
Figure 1: The build servlet
The screen shows if there's a build currently running and if so when it started. Down the left there is a history of all the builds, whether successful or not. Clicking on a build shows the details of that build: whether it compiled, status of tests, what changes were made, etc.
We've found that many developers keep a regular eye on this web page. It gives them a sense of what's going on in the project and on what's getting altered as people check in. At some point we may put other project news on that page, but we don't want it to lose its relevance.
It's important that any developer can simulate the master build locally on their own machine. That way if an integration error does occur, a developer can investigate and debug the problem on their own machine without tying up the master build process. Furthermore the developer can run the build locally before checking in to reduce the chances of the master build failing.
There's a reasonable question here about whether the master build should be a clean build, i.e. all from sources only, or an incremental build. Incremental builds can be a lot faster, but they also introduce the risk of a problem sneaking because something didn't get compiled. It also has the risk of us not being able to recreate a build. Our builds are pretty quick (about 15 minutes for ~200KLOC) so we're happy with doing a clean build each time. However some shops like to do incremental builds most of the time, but a regular clean build (at least daily) in case those odd errors crop up.
Checking in
Using an automated build means that the developers follow a certain kind of rhythm as they develop software. The most important part of that rhythm is that they integrate regularly. We've run across organizations where they do a daily build, but people don't check in frequently. If developers only check in every few weeks, then a daily build doesn't do much for you. We follow a general principle that every developer checks code in roughly once a day.
Before starting on a new task, developers should first sync with the configuration management system. This will mean that their local copies of the sources are up to date. Writing code on top of out-of-date sources only leads to trouble and confusion.
The developer then works on the task updating whichever files need changing. A developer may integrate when a task is done, or part way through a task, but all tests need to run fine in order to integrate.
The first part of integration is to resync the developers working copies with the repository. Any files changed on the repository are copied into the working directory and the configuration management system warns the developer of any conflicts. The developer then needs to build to the synchronized working set and run the BVT successfully on those files.
Now the developer can commit the new files to the repository. Once that's done the developer needs to wait for the master build. If the master build succeeds, then the check in succeeded. If not the developer can fix the problem and commit the fix if it's straightforward. If it's more complicated then the developer needs to back out the changes, resync his working directory and get things working locally before committing again.
Some check-in processes force a serialization of the check-in process. In this situation there is a build token which only one developer can take. The developer will take the build token, resync the working copy, commit the changes, and release the token. This stops more than one developer updating the repository between builds. We've found that we rarely run into trouble without the build token, so we don't use one. Frequently more than one person commits into the same master build, but only rarely does that cause a build failure: and then it's usually easy to fix.
We also leave to the developer's judgement how careful they should be before checking in. It's up to developer how likely they think it is that there will be an integration error. If she thinks it is likely, then she does a local build first before checking in, if she thinks an integration error is unlikely then she will just check in. If she's wrong she'll find out once the master build runs and then she'll have to back out her changes and figure out what went wrong. You can tolerate errors providing they are quick to find and easy to remove.
Summing up
Developing a disciplined and automated build process is essential to a controlled project. Many software gurus say that, but we've found that it's still a rarity in the field.
The key is to automate absolutely everything and run the process so often that integration errors are found quickly. As a result everyone is more prepared to change things when they need to, because they know that if they do cause an integration error, it's easy to find and fix. Once you have these benefits, you'll find they are such that you'll kick and scream before you give them up.
Significant Revisions
10 September 2000: Original publication