
Aggregate Oriented Database
19 January 2012

One of the first topics to spring to mind as we worked on Nosql Distilled was that NoSQL databases use different data models than the relational model. Most sources I've looked at mention at least four groups of data model: key-value, document, column-family, and graph. Looking at this list, there's a big similarity between the first three - all have a fundamental unit of storage which is a rich structure of closely related data: for key-value stores it's the value, for document stores it's the document, and for column-family stores it's the column family. In DDD terms, this group of data is an DDD_Aggregate.
The rise of NoSQL databases has been driven primarily by the desire to store data effectively on large clusters - such as the setups used by Google and Amazon. Relational databases were not designed with clusters in mind, which is why people have cast around for an alternative. Storing aggregates as fundamental units makes a lot of sense for running on a cluster. Aggregates make natural units for distribution strategies such as sharding, since you have a large clump of data that you expect to be accessed together.
An aggregate also makes a lot of sense to an application programmer. If you're capturing a screenful of information and storing it in a relational database, you have to decompose that information into rows before storing it away.
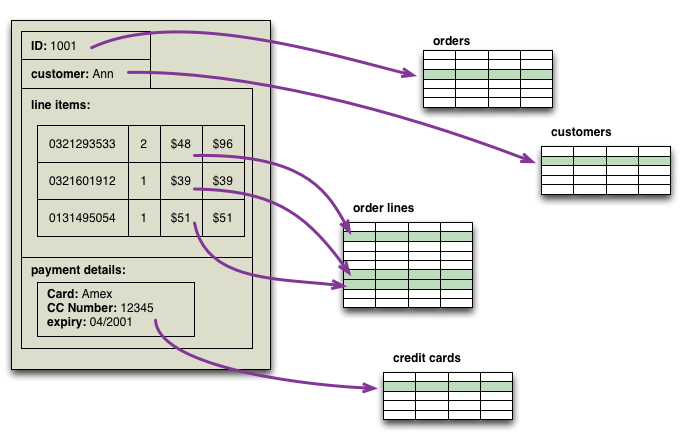
An aggregate makes for a much simpler mapping - which is why many early adopters of NoSQL databases report that it's an easier programming model.
This synergy between the programming model and the distribution model is very valuable. It allows the database to use its knowledge of how the application programmer clusters the data to help performance across the cluster.
There is a significant downside - the whole approach works really well when data access is aligned with the aggregates, but what if you want to look at the data in a different way? Order entry naturally stores orders as aggregates, but analyzing product sales cuts across the aggregate structure. The advantage of not using an aggregate structure in the database is that it allows you to slice and dice your data different ways for different audiences.
This is why aggregate-oriented stores talk so much about map-reduce - which is a programming pattern that's well suited to running on clusters. Map-reduce jobs can reorganize the data into different groups for different readers - what many people refer to as materialized views. But it's more work to do this than using the relational model.
This is part of the argument for PolyglotPersistence - use aggregate-oriented databases when you are manipulating clear aggregates (especially if you are running on a cluster) and use relational databases (or a graph database) when you want to manipulate that data in different ways.