
Eager Read Derivation
10 February 2009

One of the interesting talks I attended at QCon San Francisco, was one given by Greg Young about a particular architecture he'd used on a recent system. Greg is a big fan of Domain Driven Design, in this case it needs to be used with a system that has to process a high transaction rate and provide data to lots of users. There were a number of things I found interesting about his design, particularly his use of Event Sourcing, but for this post I want to dwell on just one aspect - what I'll call Eager Read Derivation.
When we use a Domain Model, we use it because it contains complicated domain logic. It can be helpful to classify this domain logic into:
- validations: checks that input makes sense and objects are properly suited for further actions.
- consequences: initiating some action that will change the state of the world
- derivations: figuring out some information based on information we already have
These kinds of domain logic apply differently to updates than to reads. Lets imagine we have a genealogical system. We get an update which is a birth record.
name: Bilbo Baggins
father: Bungo Baggins
mother: Belladonna Took
When we submit this data our domain model would do some validation (father isn't the same as mother). It might do some consequences (Bungo has an outstanding bequest that Bilbo would be entitled to.) It may also do some derivation, but usually only to support validation or consequences (we would need a list to Bilbo's ancestors to validate that we don't have a cycle in the family tree).
When we read data, usually only derivation logic comes into play. Say we have a request to display Bilbo's paternal grandfather. This requires some domain logic - the knowledge that a paternal grandfather is a father's father. In most systems we run this read derivation logic when we get the read request. Essentially we get the read request, call the database to pull out the raw data, run any needed derivation logic, and return the result (although caches may come into play to reduce this).
Eager read derivation does something quite different. Here reads don't touch the main database at all. Instead we have one or more ReportingDatabases that are structured in the same way as our read requests. Any read requests go directly to the reporting databases which read the data directly and push it out with no domain logic involved.
Let me say that again with the birth record example and this diagram.
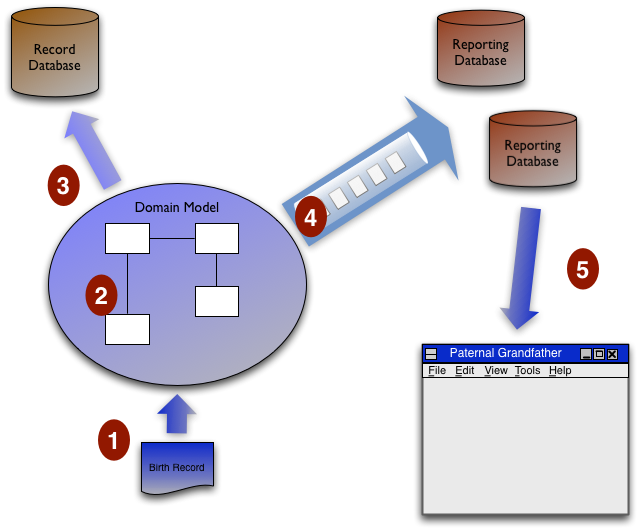
- We get a birth record come in from the UI.
- The domain model runs the all the validation and consequences logic.
- The domain model updates core information to the database of record.
- The domain model runs derivation logic required for all reads (including each UI display) and puts update messages onto a message queue to populate the reporting databases. Each reporting database selects the data it needs from these messages to update its data.
- A read request comes in from the paternal grandfather UI and is satisfied by a direct read from the paternal grandfather table in a reporting database.
In Greg's case all of this was done with asynchronous messages, all inputs were captured as events (Event Sourcing), the domain model processed the messages off the input queue and posted output events to output queues to load the reporting databases. Doing all this asynchronously helps with overall performance and scalability. It does mean there is an inconsistency window where you may do an update, immediately do a read, and not see the result of the update because you clicked faster than the messages could be processed. This asynchronous scheme is eventually consistent, but not strongly consistent. But this is the nature of the beast: in a distributed system you can get consistency or availability but not both.
Now you can do eager read derivation in a non-distributed, strongly consistent manner. I can't think off-hand of a case where I've seen it. I think eager read derivation mostly becomes attractive as you deal with high demand distributed cases.
Doing eager evaluation is hardly that new. The technique is older than me (possibly even older than Ron Jeffries) and most high-volume websites populate databases with derived data all the time. But it's not a technique I see considered as often as it should be, and I liked the aggressive way Greg had used it in his design.