Recent Changes
Here is a list of recent updates the site. You can also get this
information as an RSS feed and I announce new
articles on Fediverse (Mastodon),
Bluesky,
LinkedIn, and
X (Twitter)
.
I use this page to list both new articles and additions to existing
articles. Since I often publish articles in installments, many entries on this
page will be new installments to recently published articles, such
announcements are indented and don't show up in the recent changes sections of
my home page.
Mon 21 Apr 2025 09:07 EDT
A couple of months ago, my colleague Shayan Mohanty
published a technical overview of the series of papers describing
the deepseek AI models. He's now gone through that article, adding
more explanations to make it more digestible for those of us who don't
have a background in building these kinds of models.
more…
Thu 17 Apr 2025 09:39 EDT
AI editors like Cursor can generate code with remarkable speed using
LLMs, handling boilerplate and providing functional snippets for various
tasks. However, when building robust systems, functional correctness is
only the starting point. Code must also be safe, predictable,
maintainable, and free from subtle side effects. Unmesh
Joshi demonstrates, through a dialogue between a developer and an
LLM, how expert guidance is crucial to transform an initial, potentially
unsafe code snippet into a robust, system-ready component.
more…
Fri 04 Apr 2025 14:32 EDT
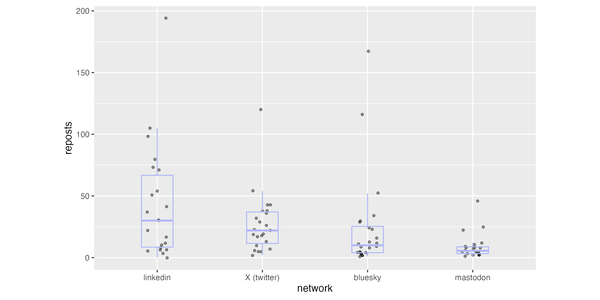
Some people asked about how many people clicked through the links on
these social media posts. I've added some more to the article, partly to
explain why I don't have that information, and partly to show overall
source data for traffic to the site.
more…
Thu 03 Apr 2025 09:41 EDT
A few years ago, whenever I published a new article here, I would just
announce it on Twitter, but since the Muskover its importance has
declined, and now I post updates to several services. To compare
engagement on these services, I've looked at reposts, likes, and replies
to two dozen of my recent posts.
more…
Tue 01 Apr 2025 17:22 EDT
I've always enjoyed reading, and for most of my life I've particularly
enjoyed reading history. I've head many great things about Robert
Caro's books, but was deterred by their size. Finally, with his
first book newly available as an ebook, I decided to dip my toes in. The
books are too good for me to escape.
more…
Tue 25 Mar 2025 10:39 EDT
As agentic coding assistants get more capable,
Birgitta Böckeler is trying them to change existing
codebases. This has led to some impressive collaboration sessions, but
she's needed to intervene, correct and steer all the time. In her latest
post, she describes examples of these interventions, giving ideas of the
types of skills we currently need to correct the tools' missteps.
more…
Wed 26 Feb 2025 11:49 EST
The new US administration has decided to eliminate the “X” option for gender/sex on passports. I have several non-binary friends, and I don’t see why they should have to select an option that makes no sense for them. I also don’t see how an “X” option on identity documents causes a material problem for anyone else. There’s not much I can do to object to this change, but one little thing is to add a comment on the Federal Register for such rule changes. There are three such pages:
DS-11 new passport application: (deadline 3/17/25) https://www.federalregister.gov/documents/2025/02/14/2025-02648/30-day-notice-of-proposed-information-collection-application-for-a-us-passport
DS-82 passport renewal: (deadline 3/20/25)
https://www.federalregister.gov/documents/2025/02/18/2025-02697/30-day-notice-of-proposed-information-collection-us-passport-renewal-application-for-eligible
DS-5504 name change or data corrections: (deadline 3/20/25)
https://www.federalregister.gov/documents/2025/02/18/2025-02696/30-day-notice-of-proposed-information-collection-application-for-a-us-passport-for-eligible
It didn’t take me more than a few minutes to make a brief comment (essentially the first three sentences of this post) on all three. Pretty inconsequential compared to the problems facing my non-binary friends.
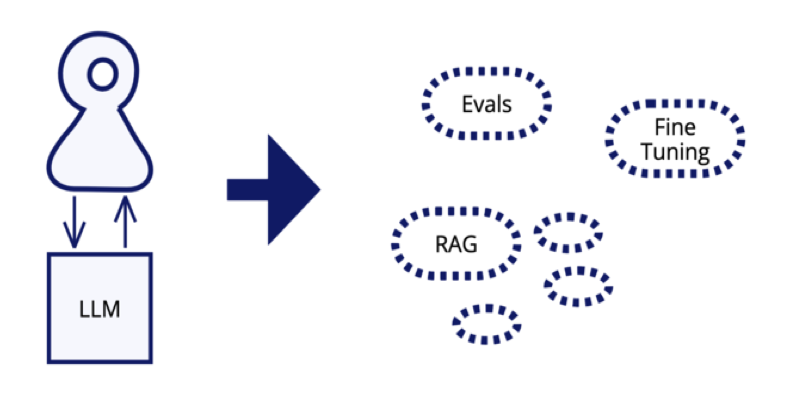
Tue 25 Feb 2025 07:20 EST
While RAG is the most common way to focus a foundation model on
material outside its training set, Bharani Subramaniam
and I now finish our current batch of patterns by examining our experience
with Fine Tuning where we learned to prioritize
curating high-quality data.
more…
Wed 19 Feb 2025 07:02
Gen AI systems are gullible, and can easily be tricked into responding
in ways that are contrary to an enterprise's policies or leak
confidential information. Bharani
Subramaniam and I describe how we can counter this by adding
guardrails at the boundaries of the request/response flow. We also
conclude our discussion of RAG with an overview of how all the RAG
component patterns fit together.
more…
Tue 18 Feb 2025 07:02
Recent LLM models have provided “reasoning” capabilities. Birgitta
Böckeler asks what role these play with coding tasks. She
doesn't have an answer, but does have questions and thoughts - and has
not found such capabilities worthwhile so far.
more…
Thu 13 Feb 2025 21:16
LLMs struggle with large amounts of context. Bharani
Subramaniam and I explain how to mitigate this common RAG
problem with a Reranker which takes the document
fragments from the retriever, and ranks them according to their usefulness.
more…
Wed 12 Feb 2025 07:58
Users often have difficulty writing the most effective queries.
Bharani Subramaniam and I explain Query Rewriting:
getting an LLM to formulate alternative queries to send to a RAG's
retriever.
more…
Thu 06 Feb 2025 09:17 EST
The appearance of DeepSeek Large-Language Models has caused a lot of
discussion and angst since their latest versions appeared at the beginning
of 2025. But much of the value of DeepSeek's work comes from the papers
they have published over the last year. Shayan Mohanty
provides an overview of these papers, highlighting three main arcs in this
research: a focus on improving cost and memory efficiency, the use of HPC
Co-Design to train large models on limited hardware, and the development
of emergent reasoning from large-scale reinforcement learning
more…
Wed 05 Feb 2025 10:03 EST
Today Bharani Subramaniam and I outline four
limitations to the simple RAG from yesterday, and the pattern that
addresses the first of these: Hybrid Retriever. This tackles the
inefficiencies of embeddings-based search by combining it with other
search techniques.
more…
Tue 04 Feb 2025 10:23 EST
was on a panel at goto Copenhagen last September with Holly Cummings,
Trisha Gee, Dave Farley, and Daniel Terhorst-North. We discussed the
current state of software development and where it was heading. Given the
timing, there was much discussion about the role AI would play in our
profession's future.
more…
Tue 04 Feb 2025 09:57 EST
A pre-trained GenAI model lacks recent and specific information about a
domain. Bharani Subramaniam and I explain how Retrieval
Augmented Generation (RAG) can fill that gap.
more…
Thu 30 Jan 2025 00:00 EST
The Forest and the Desert is a metaphor for thinking about software
development processes, developed by Beth Andres-Beck and hir father Kent Beck.
It posits that two communities of software developers have great difficulty
communicating to each other because they live in very different contexts, so
advice that applies to one sounds like nonsense to the other.
The desert is the common world of software development, where bugs are
plentiful, skill isn't cultivated, and communications with users is difficult.
The forest is the world of a well-run team that uses something like Extreme Programming, where developers swiftly put changes into
production, protected by their tests, code is invested in to keep it healthy,
and there is regular contact with The Customer.
Clearly Beth and Kent prefer The Forest (as do I). But the metaphor is more
about how description of The Forest and the advice for how to work there often
sounds nonsensical to those whose only experience is The Desert. It reminds us
that any lessons we draw about software development practice, or architectural
patterns, are governed by the context that we experienced them. It is possible
to change Desert into Forest, but it's difficult - often requiring people to do
things that are both hard and counter-intuitive. (It seems sadly easier for
The Forest to submit to desertification.)
In this framing I'm definitely a Forest Dweller, and seek with Thoughtworks
to cultivate a healthy forest for us and our clients. I work to explain The Forest to Desert
Dwellers, and help my fellow Forest Dwellers to make their forest even more
plentiful.
Acknowledgements
Kent Beck supplied the image, which he may have painstakingly drew pixel by
pixel. Or not.
Wed 29 Jan 2025 10:55 EST
GenAI systems, like many modern AI approaches, have to handle vast
quantities of data, and find similarities between elements in an image or
chunk of words. Bharani Subramaniam and I describe a key tool
to do this - Embeddings - transforming large data blocks into
numeric vectors so that embeddings near each other represent related
concepts
more…
Tue 28 Jan 2025 07:43 EST
Everyone is fascinated about using generative AI these days, and my
colleagues are no exception. Some of them have had the opportunity to put
these system into practice, both as proof-of-concept, and more importantly
as production system. I've known Bharani Subramaniam for
many years as a technology leader in India, he's been assembling the
lessons we've learned and I've worked with him to describe them as
patterns.
In this first installment, we look the limits of the base case of
Direct Prompting, and how we might assess the capability of a system using
Evals.
more…
Fri 24 Jan 2025 13:01 EST
Luca Rossi hosts a podcast (and newsletter) called Refactoring, so it's
obvious that we have some interests in common. The tile comes from me
leaning heavily on Beth Anders-Beck and Kent Beck's metaphor of The Forest and The Desert. We talk
about the impact of AI on software development, the metaphor of technical
debt, and the current state of agile software development.
more…
Wed 22 Jan 2025 10:54 EST
Juntao Qiu finishes his description of codemods by
looking at some other approaches outside the JavaScript world such as
JavaParser and OpenRewrite.
more…
Wed 15 Jan 2025 11:43
So far the codemods that Juntao Qiu has described are
fascinating, but rather straightforward. Real codebases offer more
challenges. In this installment, he goes into how to tackle more
complicated cases by composing codemods.
more…
Thu 09 Jan 2025 09:49 EST
I've got into the habit of starting the New Year by sharing six
favorite albums I discovered during the last year. This years set includes
Celtic jazz, trip-hop neo-fado, jazz-fusion for the 2020's, playful
harmonies, and a vibrant collaboration between Indian classical musicians and a
string quartet. (I was also unable to limit myself to six.)
more…
Wed 08 Jan 2025 09:44 EST
Juntao Qiu moves onto a more complex example of a
codemod, one that extracts a tooltip responsibility from a JSX component.
This illustrates how to manipulate the AST in several steps.
more…
Tue 07 Jan 2025 09:34 EST
As a library developer, you may create a popular utility that hundreds
of thousands of developers rely on daily, such as lodash or React. Over
time, usage patterns might emerge that go beyond your initial design. When
this happens, you may need to extend an API by adding parameters or
modifying function signatures to fix edge cases. The challenge lies in
rolling out these breaking changes without disrupting your users’
workflows. Juntao Qiu begins an article to explain how we
can use codemods to tackle this. Codemods are a tool automating
large-scale code transformations, allowing developers to introduce
breaking API changes, and refactor legacy codebases.
more…
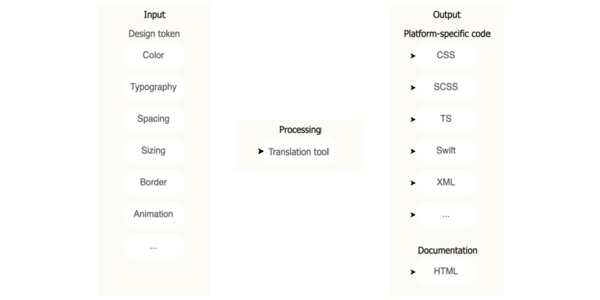
Thu 12 Dec 2024 10:36
Design tokens are fundamental design decisions represented as data.
Andreas Kutschmann explains how they work
and how to organize them to balance scalability, maintainability and
developer experience.
more…
Tue 10 Dec 2024 15:22
Once we've designed our initial data products, Kiran
Prakash finishes his article by leading us through the
next steps: identifying common patterns, improving the developer
experience, and handling governance.
more…
Wed 04 Dec 2024 10:36 EST
Having got an initial data product, Kiran Prakash
leads us through the next steps: covering similar uses cases to
generalize the data product, determining which domains the products fit
into, and considering service level objectives.
more…
Tue 03 Dec 2024 09:04 EST
Increasingly the industry is seeing the value of creating data
products as a core organizing principle for analytic data. Kiran
Prakash has helped many clients design their data products, and
shares what he's learned. In particular his methodical approach doesn't
begin by thinking about some data that might be handy to share, but
instead works from what consumers of a data product need.
more…
Tue 19 Nov 2024 10:17 EST
A very powerful new coding assistance feature made its way into GitHub
Copilot at the end of October. This new “multi-file editing” capability
expands the scope of AI assistance from small, localized suggestions to
larger implementations across multiple files. Birgitta
Böckeler tries out this new capability and finds
out how useful its changes tend to be, and wonders about what feedback
loops are needed with them.
more…